
Bias Audits for Agentic Systems: Tests, Tools, and Mitigation
Tags: LLM Bias Mitigation, Bias Audits, Fairness in AI Agents, Explainability Tools
AI agents today are increasingly being used in decision-making processes - from resume screening and financial approvals to customer support and healthcare analytics. But as their influence grows, so does the need for fairness, transparency, and accountability.
Even the most advanced agentic systems (AI agents capable of reasoning, memory, and planning) can exhibit bias i.e unintended favoritism or prejudice in outputs. Bias can arise from training data, model architecture, or even prompt design. If left unchecked, these biases can lead to real-world harm and reputational damage.
This article explores how to conduct bias audits for agentic systems, covering:
Types of bias in LLM-based agents
Frameworks and tools for bias detection
Fairness metrics and testing methodologies
Mitigation strategies and explainability techniques
1. What is Bias in Agentic Systems?
Bias in AI agents refers to systematic errors that lead to unfair or prejudiced outcomes. It manifests when an AI agent’s decisions consistently favor or disfavor certain groups or attributes (e.g., gender, ethnicity, language).
Common Sources of Bias
Training Data Bias – Models trained on unbalanced or prejudiced data reproduce those biases.
Example: If training data overrepresents one demographic, the model’s outputs may favor that group.
Algorithmic Bias – The model’s architecture or optimization criteria amplify preexisting patterns.
Example: LLMs that optimize for fluency may reinforce stereotype-laden language.
Prompt and Context Bias – Even the structure or wording of prompts can lead to biased outcomes.
Example: Asking “Who is the best leader?” may produce different answers based on cultural or linguistic context.
Feedback Loops – When agentic systems learn from user feedback, they might amplify prevailing biases.
2. Why Bias Audits Are Critical
Bias audits ensure that agentic systems are:
Trustworthy: Reducing bias improves model credibility and user trust.
Compliant: Regulations like the EU AI Act, GDPR, and US Algorithmic Accountability Act require documentation of fairness measures.
Ethically Responsible: Preventing discriminatory outcomes aligns AI systems with human rights and social values.
Moreover, bias audits are not a one-time process. They should be part of the continuous model governance lifecycle.
3. Types of Bias to Audit
When auditing AI agents, it’s essential to classify bias types based on their origin and effect.
Type of Bias | Description | Example |
|---|---|---|
Representation Bias | Underrepresentation of certain groups in training data | Fewer female leadership examples in datasets |
Label Bias | Mislabeling or inconsistent labeling of groups | “Aggressive” labeled more for certain ethnic groups |
Measurement Bias | Faulty measurement or proxy variables | Using zip code as a proxy for income level |
Temporal Bias | Outdated data that doesn’t reflect current reality | Old job market data influencing recommendations |
Selection Bias | Sampling not representative of the population | Model trained mostly on Western English sources |
A proper audit must detect all these forms across data, model, and workflow stages.
4. Tools and Frameworks for Bias Detection
Numerous open-source and enterprise-grade tools help perform bias audits and fairness assessments for agentic systems.
a. Fairlearn (Microsoft)
Provides metrics for fairness across demographic groups.
Includes visualization tools for performance disparities.
Supports multiple fairness definitions (equal opportunity, demographic parity).
Example (Python):
This code computes model accuracy and selection rate by demographic group, exposing fairness gaps.
b. AIF360 (IBM AI Fairness 360)
Offers over 70 bias metrics and mitigation algorithms.
Detects bias at the data preprocessing, model, and postprocessing stages.
Example: Evaluate disparate impact ratio:
If the disparate impact ratio < 0.8, it indicates potential bias against an unprivileged group.
c. LlamaIndex / LangChain Bias Checkers
For LLM agents, bias may stem from prompt construction or retrieval-augmented generation (RAG). These frameworks now integrate bias evaluation modules to track:
Toxicity in generated text
Demographic skew in retrieved examples
Sentiment bias toward certain topics
d. Hugging Face Evaluate + Perspective API
Hugging Face’s evaluation tools can measure:
Sentiment polarity
Toxicity
Gender and racial bias indicators
Example (Toxicity Audit):
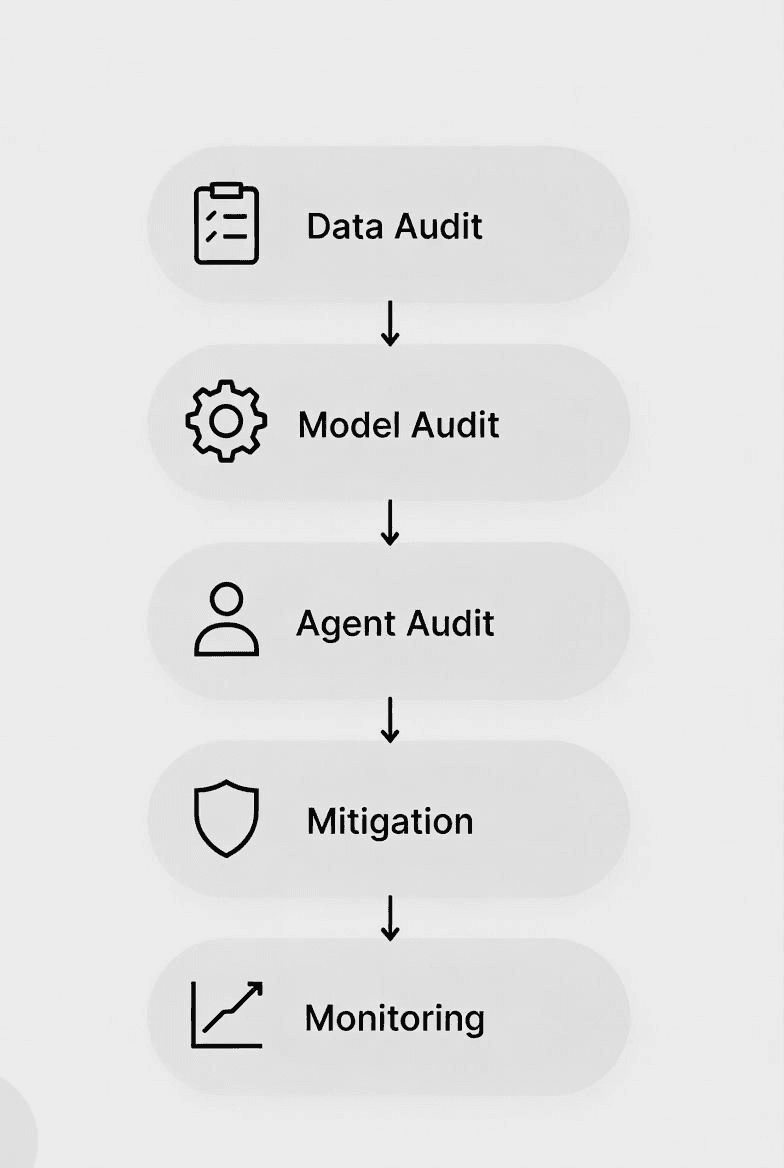
5. Bias Testing Workflow for Agentic Systems
Conducting a bias audit involves structured testing across the data, model, and interaction layers.
Step 1: Data Audit
Analyze dataset composition: Ensure demographic balance across attributes like gender, ethnicity, geography.
Detect annotation skew: Validate consistency of labels across demographic subgroups.
Perform stratified sampling: Create balanced test sets.
Step 2: Model-Level Audit
Use fairness metrics like:
Demographic Parity (DP): P(predicted=1 | group A) ≈ P(predicted=1 | group B)
Equal Opportunity (EO): Equal true positive rates across groups
Disparate Impact (DI): Ratio of favorable outcomes between privileged/unprivileged groups
Compute these using frameworks like Fairlearn or AIF360.
Step 3: Agent Behavior Audit
For agentic systems, audit prompts and decision logic:
Test prompts with varied names, accents, and contexts.
Measure consistency in responses (e.g., same query with different demographic cues).
Log reasoning traces to identify biased decision branches.
Step 4: Human Review and Documentation
Summarize results in bias audit reports.
Include metrics, findings, and remediation steps.
Document for compliance and governance reviews.
6. Explainability and Traceability
Bias audits go hand-in-hand with explainability. Understanding why an agent made a decision helps pinpoint and correct bias.
Techniques:
SHAP (SHapley Additive exPlanations)
Explains feature contributions to predictions, useful for identifying bias in inputs.
This plot highlights which features (like age or gender) influence outcomes most.
LIME (Local Interpretable Model-agnostic Explanations)
Provides local explanations for specific outputs.
Prompt Trace Logging (for LLM Agents)
Capture full prompt-response pairs with context metadata for post-hoc analysis.
Vector Memory Inspection
For memory-enabled agents, inspect stored embeddings to ensure they’re not skewed toward specific demographic representations.
7. Mitigation Strategies
After identifying bias, the next step is mitigation. Strategies vary by system layer.
a. Data-Level Mitigation
Rebalancing: Augment underrepresented groups through synthetic data generation.
De-biasing techniques: Remove sensitive attributes (e.g., gender) or reduce their influence via adversarial training.
Data reweighting: Assign lower weights to overrepresented samples.
b. Model-Level Mitigation
Fairness Constraints: Add fairness regularizers in model optimization.
Adversarial De-biasing: Train a model that minimizes both prediction loss and bias detection accuracy.
Postprocessing Adjustments: Calibrate outputs to meet fairness thresholds (e.g., equal opportunity post-hoc correction).
c. Agent-Level Mitigation
Prompt Neutralization: Rewrite or reframe prompts to eliminate bias-inducing words or patterns.
Response Filtering: Use toxicity filters or sentiment checkers before presenting results.
Memory Sanitization: Periodically clean long-term memory to remove biased or low-quality context.
Example (Prompt Sanitization Pipeline):
8. Continuous Monitoring and Governance
Bias is not static because models drift over time. Regular monitoring ensures long-term fairness.
Continuous Auditing Checklist
Task | Frequency | Tools |
|---|---|---|
Data composition review | Monthly | Pandas Profiling, AIF360 |
Fairness metric recalculation | Weekly | Fairlearn |
Agent prompt audits | Ongoing | LangChain trace logs |
Human review & governance | Quarterly | Compliance dashboards |
Governance Practices
Maintain Bias Audit Logs for regulatory compliance.
Establish AI Ethics Boards to review decisions and recommend interventions.
Integrate results into model documentation (Model Cards, System Cards).
9. Case Example: Auditing a Recruitment Agent
Scenario:
An AI recruitment agent screens job applications and shortlists candidates.
Audit Findings:
Detected higher selection rates for male applicants.
Resume parser learned gender correlations from training data (e.g., “he” in reference letters).
Mitigation Steps:
Removed gender-identifiable words from training data.
Added fairness constraint to classifier (equal opportunity).
Deployed a real-time audit monitor using AIF360 + Prometheus.
Result:
Selection rate parity improved from 0.65 to 0.91 across gender groups after mitigation.
Bias audits are essential to building trustworthy, ethical, and legally compliant agentic systems.
They ensure fairness across demographic groups and maintain transparency in AI decision-making.
By integrating bias detection tools (Fairlearn, AIF360), explainability frameworks (SHAP, LIME), and mitigation strategies (rebalancing, prompt neutralization), organizations can create agents that are fair, transparent, and accountable.
Bias auditing is not a one-time task. It’s a continuous process of measurement, documentation, and improvement. The goal is not just to remove bias but to build equitable AI systems that serve everyone fairly.
