
Memory Systems for AI Agents: Short-term vs Long-term Designs
Tags: AI Agent Memory, Vector Databases, LLM Memory Systems, Agentic Architecture
AI agents are becoming increasingly capable of reasoning, planning, and interacting with complex workflows. But their true power lies in memory i.e the ability to recall past context, maintain continuity, and learn over time.
Without memory, even the most advanced large language model (LLM) is like a goldfish because it processes each prompt in isolation, forgetting everything once the session ends.
This article dives deep into the architecture of AI memory systems, explaining how short-term and long-term memory work, how they’re implemented, and why the right design dramatically improves accuracy, contextual understanding, and human-like interaction.
1. Why Memory Matters in AI Agents
An agent’s ability to reason effectively depends on how well it can:
Recall prior steps in a conversation or task
Learn from previous outcomes
Retrieve relevant context from large knowledge stores
Memory enables:
✅ Context continuity - retaining user goals and history
✅ Adaptive behavior - modifying responses based on past feedback
✅ Scalability - storing experiences for future tasks
For example, a support AI agent can remember that a customer had an unresolved ticket last week, or a data pipeline agent can recall transformation logic from a previous run.
2. Types of Memory in AI Agents
a. Short-Term Memory (STM)
Definition:
Short-term memory holds the immediate context of an ongoing conversation or task. It’s ephemeral as once the session or workflow ends, it’s cleared.
Use case:
Conversational turns in a chatbot
Maintaining local variables during multi-step reasoning
Retaining temporary results (like a current API call response)
Implementation Example:
Here, the buffer memory stores conversation context for the session.
b. Long-Term Memory (LTM)
Definition:
Long-term memory retains knowledge across sessions. It allows agents to recall past interactions, user preferences, or processed data even after restarts.
Use case:
Remembering previous user tasks
Accessing knowledge bases (documents, embeddings, summaries)
Learning from feedback loops and corrections
Implementation Flow:
Common Tools:
Vector databases: Pinecone, Weaviate, FAISS, Milvus
Storage layers: Redis, PostgreSQL, MongoDB (with embedding extensions)
Example:
A project management agent recalls previous tasks:
“You assigned this report to Alex last week. Do you want to follow up?”
That’s long-term memory in action : powered by vector similarity retrieval.
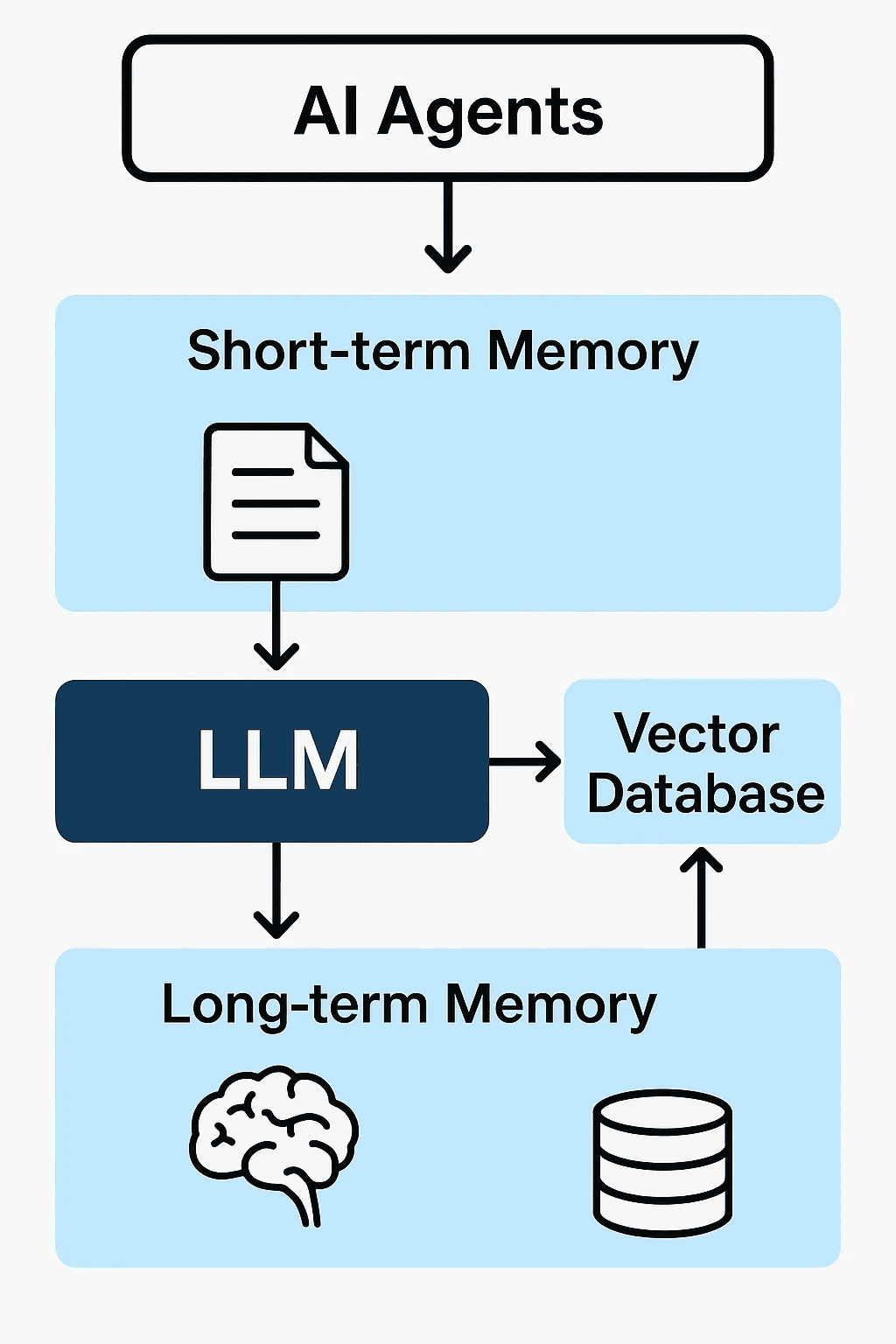
3. Architectural Design: Memory Layers
Memory Architecture Diagram
I’ll include this after the text for better context.
Core Components
Memory Interface: Defines how the agent reads/writes memory (API or wrapper).
Embedding Model: Converts text into numerical vectors (e.g., OpenAI, Cohere, or HuggingFace models).
Vector Store: Stores and retrieves vectors based on semantic similarity.
Retriever: Queries relevant context chunks based on new input.
Memory Manager: Decides what to retain, forget, or summarize.
Data Flow
Short-term memory (STM) provides local context, while long-term memory (LTM) supplies historical grounding.
4. Memory Management Strategies
a. Rolling Window Memory
Keeps only the last n interactions. Prevents token overflow but loses early context.
Ideal for: Short tasks, chatbots
Implementation:
ConversationBufferWindowMemory(LangChain)
b. Summarized Memory
Older messages are summarized periodically and stored in long-term memory.
Reduces token cost
Retains key information
Example:
c. Episodic Memory
Stores structured “episodes” (task + context + result).
Useful for reasoning agents that need historical recall.
Example structure:
d. Contextual Memory Filtering
Applies relevance scoring (via cosine similarity) to retrieve only the most relevant past data.
Prevents context dilution
Ensures low-latency retrieval
5. Comparing Short-term vs Long-term Memory
Attribute | Short-term Memory | Long-term Memory |
|---|---|---|
Duration | Active session only | Persistent across sessions |
Storage Type | RAM / temporary buffer | Vector DB or persistent store |
Access Speed | Very fast | Slightly slower (depends on retrieval) |
Capacity | Limited (token-bound) | Scalable |
Maintenance | Auto-reset | Requires periodic pruning |
Best for | Conversations, live context | Knowledge recall, personalization |
6. Performance Considerations
Latency
STM: negligible (<50ms)
LTM (Vector DB retrieval): ~100–300ms
Use asynchronous queries and caching to maintain UX responsiveness.
Cost
STM: token usage only
LTM: token + embedding + storage cost
You can lower costs by embedding only summaries or metadata, not raw data.
Scalability
Sharding vector databases by topic (e.g., “finance,” “support,” “engineering”) helps scale efficiently without retrieval slowdowns.
7. Practical Implementation Patterns
LangChain Example (Combined Memory)
Semantic Kernel Equivalent
n8n Integration
Use n8n’s data store nodes for short-term state.
Use Pinecone or Weaviate API nodes for long-term recall.
Pass combined context to the AI node before response generation.
8. Common Challenges & Solutions
Challenge | Solution |
|---|---|
Context drift | Re-summarize old memory periodically |
Token overflow | Use dynamic trimming (top-N relevant context) |
Duplicate embeddings | Hash content before storing |
Latency | Cache frequent queries or use batch retrieval |
Privacy & Security | Encrypt memory vectors, anonymize metadata |
9. Future of AI Memory Systems
The next wave of agentic systems will move toward autonomous memory optimization, where agents decide what to remember and what to forget.
Emerging trends:
Self-organizing memory graphs (using LangGraph or LlamaIndex memory modules)
Neural memory fusion - combining embeddings with symbolic data
Adaptive memory pruning via attention weights
Collaborative multi-agent memory - agents sharing context over vector networks
By 2026, expect enterprise AI agents to use hybrid memory architectures capable of balancing precision, cost, and personalization.
Memory is not just a component. Infact it’s the core intelligence layer that makes AI agents human-like. Short-term memory ensures real-time contextual fluency; long-term memory provides continuity and learning.
The key is not choosing one over the other but designing a layered system that combines both efficiently.
Organizations adopting such memory-aware architectures will see agents that truly understand, learn, and evolve with every interaction.
