
Multi-Agent Workflow for Data Pipelines: Generator, Validator, Aggregator
Tags: Multi-Agent Pipelines, Agent Coordination, Data Pipeline Automation, Shared Memory Vector DB
In the world of data engineering, building scalable, resilient pipelines requires more than just automating individual steps. The next generation of data workflows leverages multi-agent systems i.e collections of autonomous agents that coordinate tasks, validate data, and aggregate results in a robust, adaptive way.
In this article, we’ll explore how to construct a multi-agent workflow for data pipelines, featuring three core agents: Generator, Validator, and Aggregator. We'll discuss how these agents collaborate using shared memory (e.g., vector DB), handle state transitions, and manage failure recovery.
1. What Is a Multi-Agent Data Pipeline?
A multi-agent data pipeline consists of distinct agents, each responsible for specific tasks. These agents interact autonomously and asynchronously, often sharing state or context in distributed memory.
For example:
Generator Agent: Retrieves or generates data (e.g., API, database, file reading).
Validator Agent: Ensures the data meets predefined rules or quality standards.
Aggregator Agent: Combines, transforms, or formats the validated data for downstream use (e.g., storing in a data warehouse, reporting).
These agents collaborate to ensure the pipeline is efficient, fault-tolerant, and scalable.
Key Concepts:
Agent Coordination: Each agent works in parallel but must communicate with others.
Shared Memory: Agents share information through a common memory space, often a vector database for high-speed retrieval.
Failure Recovery: In case of errors or missing data, the system must handle retries, alternative actions, or manual intervention.
2. Why Use a Multi-Agent Architecture for Data Pipelines?
Advantages:
Modularity: Each agent is isolated and can be developed, scaled, or updated independently.
Scalability: Additional agents can be added to handle new tasks or data sources.
Fault Tolerance: If one agent fails, others can continue working, and the system can recover or retry operations.
Parallelism: Agents can execute tasks in parallel, optimizing resource utilization.
Real-World Example:
Consider a data pipeline designed for processing IoT sensor data:
The Generator collects raw data from thousands of sensors.
The Validator checks for missing readings or outliers.
The Aggregator combines this validated data and stores it for analysis.
This structure allows each part of the pipeline to run autonomously, without requiring centralized control.
3. Designing the Multi-Agent Workflow: Generator, Validator, Aggregator
Let’s dive into the architecture of this multi-agent system:
Core Agents
Generator Agent:
Responsibilities: Fetches or generates raw data.
Use cases: Collecting data from external APIs, scraping websites, reading files from a data lake.
Output: Raw data in a structured format (JSON, CSV, etc.).
Validator Agent:
Responsibilities: Validates the data integrity, checks for missing values, and verifies the schema.
Use cases: Ensuring data quality before processing further (e.g., rejecting incomplete records).
Output: Validated data or error flags.
Aggregator Agent:
Responsibilities: Aggregates, transforms, and prepares the data for storage or downstream processing.
Use cases: Summing values, creating reports, or moving data to a different format.
Output: Aggregated data, reports, or data ready for storage.
4. Architecture Diagram
I’ll include a diagram after the text showing the interaction between the Generator, Validator, and Aggregator agents using shared memory (vector DB) to pass data and states.
Key Components of the System:
Shared Memory (Vector Database): A database (like Pinecone, Weaviate, or FAISS) stores the data between the agents. The memory enables agents to retrieve and store results as they collaborate.
State Transitions: Each agent updates the state of the pipeline. For example:
The Generator stores raw data in memory.
The Validator stores either validated data or error logs.
The Aggregator combines and stores final results.
5. Sample Python Code for Agent Coordination
Here’s an example of how to implement the multi-agent pipeline using Python and LangChain.
Explanation:
Generator: Fetches data, stores it in shared memory.
Validator: Checks data, stores either valid data or error messages.
Aggregator: Performs aggregation or transformation.
The memory stores each step’s output for easy retrieval and further processing.
6. State Transitions and Failure Recovery
In a multi-agent system, ensuring smooth state transitions and effective failure recovery is crucial. Here are key patterns:
State Transitions
Each agent stores its output in shared memory (e.g., a vector database).
The next agent in the workflow retrieves this memory, processes it, and updates the state.
If the agent encounters an issue, it can leave an error message in the memory, which can be monitored.
Failure Recovery Patterns
Retries: Automatically retry failed operations, either by the agent itself or via an orchestrator.
Fallback Strategies: If validation fails, move to a fallback agent or data source.
Manual Intervention: Set up alerts that trigger manual intervention if errors persist beyond a retry threshold.
Example of Failure Recovery (Retry Logic)
This logic ensures agents are robust and can handle transient failures.
7. Performance Considerations
Latency
Multi-agent workflows introduce slight delays due to agent communication and shared memory access. Use asynchronous execution and caching (e.g., Redis) to reduce latency.
Scalability
Horizontal Scaling: Add more instances of each agent to handle higher volumes of data.
Parallel Processing: Split the data into smaller chunks and process them in parallel by different agent instances.
8. Security and Privacy
For data-sensitive workflows:
Ensure that shared memory (e.g., vector DB) is encrypted.
Use role-based access control (RBAC) to restrict which agents can read/write to memory.
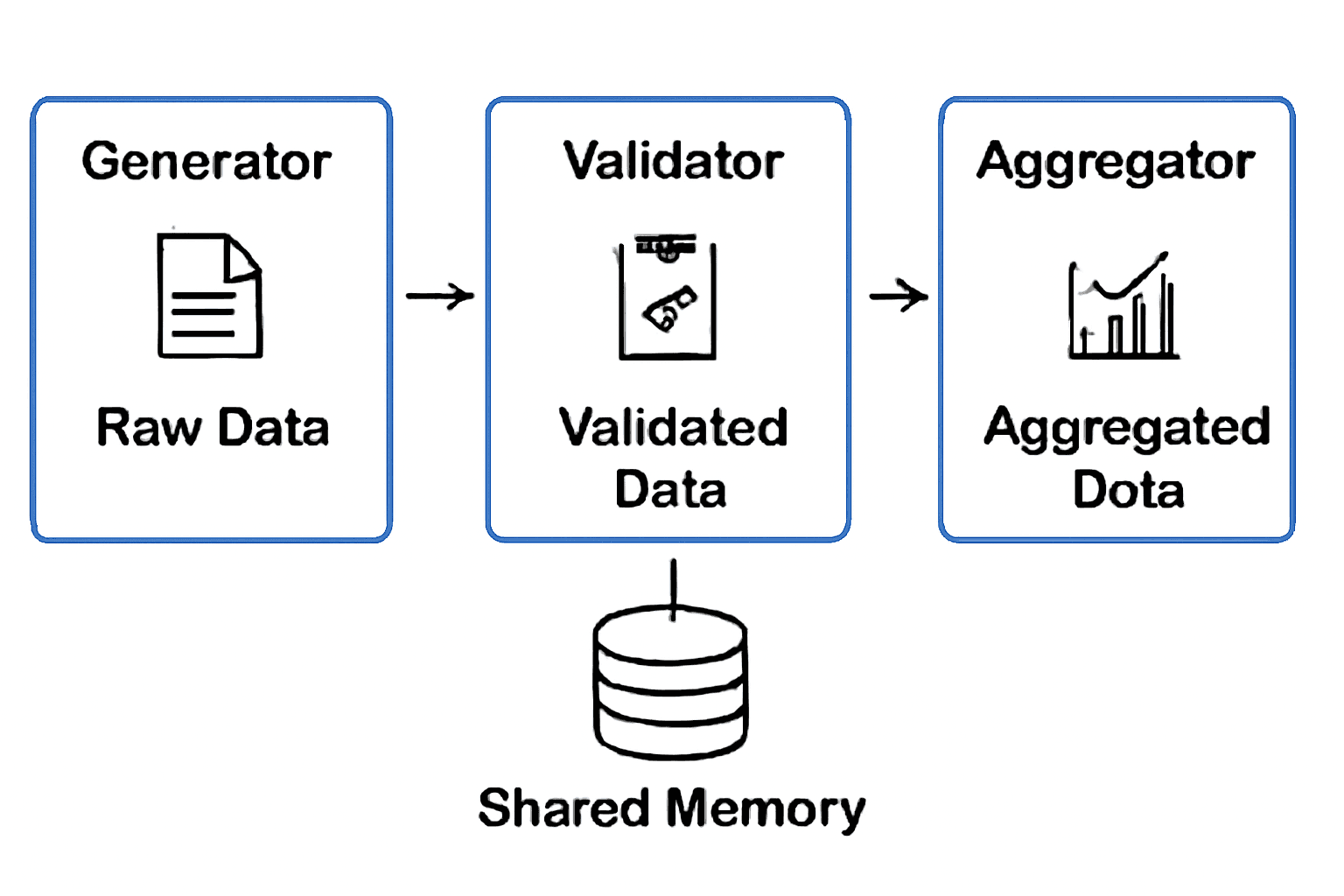
Multi-agent architectures offer a powerful approach to building scalable and resilient data pipelines. By breaking the pipeline into autonomous agents (Generator, Validator, Aggregator), you ensure each step is isolated, parallelizable, and robust to failures.
With shared memory (e.g., vector DBs), agents can efficiently communicate and process large volumes of data. The failure recovery mechanisms and state transitions ensure that your data pipeline remains operational even under adverse condit
